
As someone deeply embedded in the Microsoft Fabric ecosystem, I’ve spent considerable time building scalable dataflows, orchestrating pipelines, and structuring data in Lakehouses. However, a recent project required me to pivot and explore the AWS data platform to evaluate how self-service ETL (Extract, Transform, Load) can be implemented using Amazon’s native services.
This experience gave me the opportunity to compare AWS’s offerings with Fabric’s, especially around self-service data preparation and enterprise-grade transformation. The result? A powerful set of tools that enable data engineers and citizen data analysts alike to design, manage, and visualize ETL pipelines without heavy code dependency.
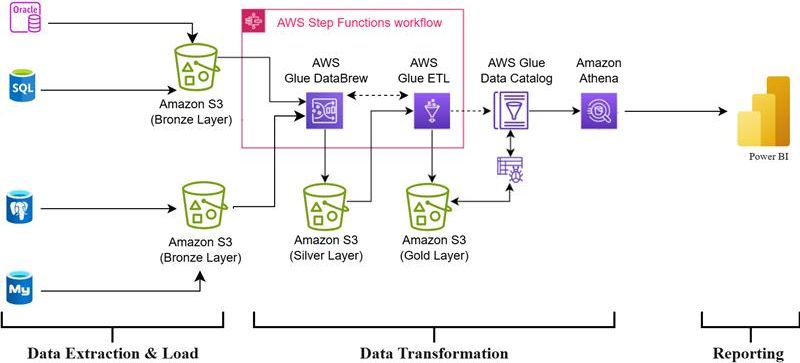
Let’s take a deep dive into the architecture I implemented — shown in the diagram below — and break down each component:
🧱 Architectural Overview: Layered Data Lake + Glue + Athena

The architecture follows a bronze-silver-gold data lake pattern, supported entirely by AWS native services:
🔹 Phase 1: Data Extraction & Load (Raw Ingestion)
At the ingestion stage, data is sourced from multiple relational databases, such as:
- Oracle
- SQL Server
- PostgreSQL
- MySQL
Each source pushes raw data (without transformation) into Amazon S3, organized into the Bronze Layer. This layer serves as a raw, immutable landing zone. The data is typically stored in CSV, JSON, or Parquet format. This separation of raw data is a critical design choice, enabling traceability and reprocessing when needed.
You can ingest this data via:
- AWS Glue connectors
- AWS DMS (Database Migration Service)
- Custom Lambda jobs or Step Functions
- Third-party ELT tools like Fivetran or Matillion
🔹 Phase 2: Data Transformation (Self-Service ETL)
Once raw data lands in S3, transformation begins in a controlled, repeatable fashion using AWS Glue DataBrew and AWS Glue ETL.
✅ AWS Glue DataBrew
Glue DataBrew is a no-code data preparation tool that enables users (data analysts, BI developers) to:
- Profile data with automated statistics
- Clean nulls, rename columns, detect data types
- Apply basic transformations through 250+ built-in operations
- Schedule and monitor jobs using AWS Step Functions
The output of DataBrew flows into the Silver Layer — cleaned and normalized datasets ready for enrichment or downstream processing.
✅ AWS Glue ETL
For more complex transformation logic — involving joins, window functions, or Python/Scala-based custom logic — Glue ETL comes into play.
Glue ETL offers:
- Serverless Spark-based execution
- Python or Scala scripting (PySpark, SparkSQL)
- Integration with AWS Glue Jobs and Workflows
Data processed via Glue ETL is stored in the Gold Layer, which holds enriched, query-optimized, and business-ready datasets. These datasets are often partitioned, compressed (Snappy, Gzip), and stored in columnar formats like Parquet for cost-efficient analytics.
💡 A common practice is to orchestrate both Glue DataBrew and Glue ETL pipelines using AWS Step Functions, ensuring sequential execution, conditional logic, and failure handling across multiple stages.
🔹 Phase 3: Metadata & Query Layer
🧬 AWS Glue Data Catalog
As datasets evolve across the Bronze → Silver → Gold stages, managing metadata becomes crucial. This is where the AWS Glue Data Catalog provides immense value:
- Schema registry for S3 datasets
- Partition indexing
- Table definitions compatible with Athena, EMR, and Redshift Spectrum
By crawling the S3 buckets or registering tables manually, the catalog provides a single source of truth for all datasets.
🔹 Phase 4: Reporting & Analytics
The final component is Amazon Athena, a serverless SQL engine that queries data directly from S3. Athena leverages the Glue Data Catalog to query structured data using ANSI SQL.
Key benefits:
- No infrastructure to manage
- Pay-per-query model (based on data scanned)
- Fast performance with Parquet + partitioning
Using Power BI, I was able to connect directly to Athena via the ODBC connector, enabling interactive dashboards and ad-hoc reporting on top of the transformed datasets — just like in a traditional SQL environment.
🔍 Why This Matters: Enabling Self-Service at Scale
This architecture represents a shift towards self-service data engineering in AWS. Similar to Microsoft Fabric’s Dataflows and Pipelines, AWS enables technical and semi-technical users to collaborate on ETL workloads with minimal DevOps overhead.
✅ Benefits of This Design:
- Separation of concerns via Bronze/Silver/Gold layers
- Reusability of data assets across teams
- Serverless architecture = zero infrastructure management
- Low-code/no-code options with Glue DataBrew
- Unified metadata with Glue Data Catalog
- Seamless reporting via Athena → Power BI
⚖️ Final Thoughts
While Microsoft Fabric excels with its seamless integration between OneLake, Power BI, and Pipelines, AWS offers an equally powerful modular approach. The key difference lies in how much abstraction you need. Fabric is opinionated and integrated, AWS is flexible and granular.
If your organization is already on AWS, embracing tools like Glue DataBrew, Glue ETL, and Athena can enable a highly scalable and user-friendly data platform — without needing to set up and maintain Spark clusters or Airflow DAGs manually.
Would I use it again? Absolutely. Especially for teams looking to democratize ETL without giving up enterprise-scale governance and performance.