
While developing a Power BI report connected directly to a Lakehouse in Microsoft Fabric, I recently encountered a common yet frustrating challenge—sorting month names chronologically. What could have turned into hours of rework and data wrangling was resolved with just two lines of SQL in a Fabric notebook, saving me significant time and effort.
Here’s a detailed breakdown of the issue, the constraints, and how Fabric’s integrated notebook experience enabled a quick and elegant solution.
🧩 The Scenario: Semantic Model on a Lakehouse Table
In my architecture, the Power BI report was built on top of a Direct Lake semantic model—a powerful new integration in Microsoft Fabric that allows Power BI to query Lakehouse tables directly, bypassing the need for importing data or pre-aggregated datasets.
This approach is ideal for near real-time reporting and large-scale data workloads, but it also means that the data model is tightly coupled with the Lakehouse schema.
The semantic model included a standard calendar (date dimension) table, used for time-based filtering, grouping, and sorting. This table already had a Month Name column, which looked fine in a slicer or a table visualization—until I noticed that the months were sorted alphabetically:
April
August
December
February
...
This happens because textual sorting doesn’t recognize calendar order. What I needed was a Month Number column (1 = January, 2 = February, etc.) to apply a custom sort order in Power BI.
🛑 The Blocker: Schema Limitations in Dataflows Gen2
The first instinct in many Power BI projects would be to go back to the data preparation layer—Power Query, or more specifically, Dataflows Gen2 in Microsoft Fabric—and add the missing Month Number column there.
However, here’s where things got tricky:
❗ When using Dataflows Gen2 to load data into a Fabric Lakehouse, you cannot alter the schema of existing tables. Schema changes such as adding new columns are currently not propagated to the Lakehouse unless the table is dropped and recreated.
Recreating the table would mean:
- Losing lineage in the semantic model
- Re-binding tables and fields
- Potentially breaking report visuals or measures
This was too risky and time-consuming for such a simple fix.
💡 The Solution: Use a Fabric Notebook to Alter the Lakehouse Table
Instead of going the long route, I turned to Fabric Notebooks, which allow you to run code (SQL, PySpark, etc.) directly against Lakehouse tables.
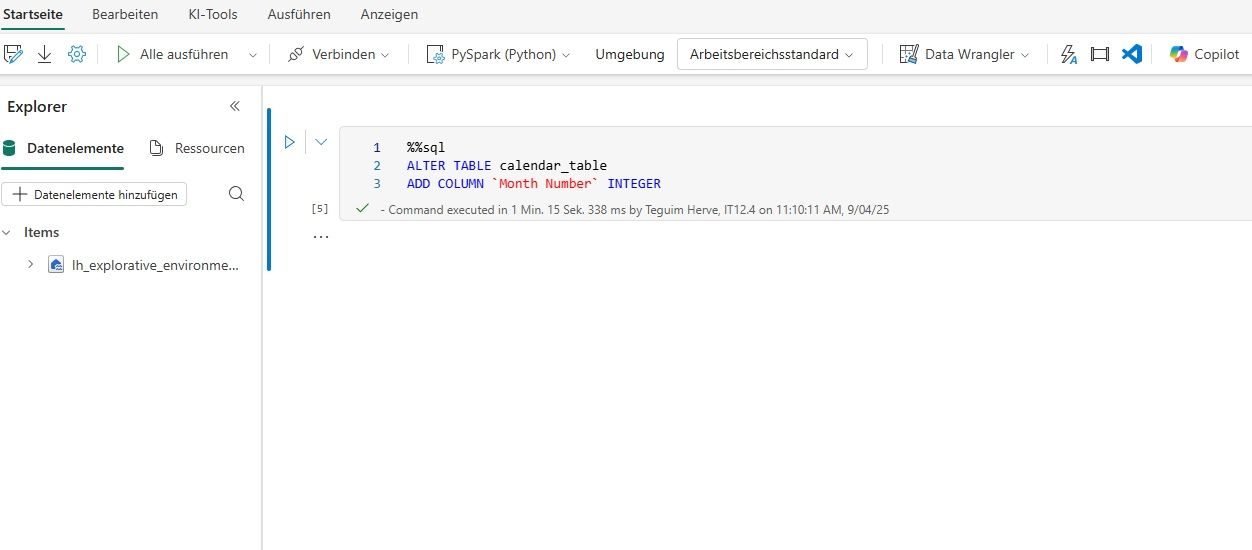
With a few keystrokes, I opened a notebook and ran the following SQL command:
ALTER TABLE calendar_table
ADD COLUMN `Month Number` INTEGER;
This command:
- Directly modified the Lakehouse table schema, adding a new nullable column
- Did not require reloading or recreating the table
- Preserved the existing semantic model bindings in Power BI
- Enabled me to fill in the new column using a simple
UPDATEor in future dataflows
Just like that, the Month Number field was available in the model, allowing me to apply the correct sort order in Power BI visuals.
🎯 Key Takeaways
- Fabric Lakehouse is schema-on-write, meaning schema changes must be handled explicitly.
- Dataflows Gen2 currently do not support adding columns to existing Lakehouse tables.
- Fabric Notebooks offer a flexible, low-friction way to run SQL against Lakehouse tables—ideal for schema tweaks or quick data fixes.
- Even in a modern data stack, classic reporting problems like date sorting still pop up—but new tools make solving them faster than ever.
📌 Bonus Tip: Populate the New Column with SQL or Dataflows
After adding the column, you can use an additional SQL statement to populate it:
UPDATE calendar_table
SET `Month Number` = MONTH(`Date`);
Or, use a Dataflow to update the values during a scheduled refresh if you prefer low-code options.
🔚 Final Thoughts
This small example highlights one of the strengths of Microsoft Fabric: the ability to interweave declarative analytics (Power BI) with data engineering capabilities (SQL/Notebooks) in a unified environment. What could have been a frustrating blocker turned into a two-minute fix—thanks to the flexibility of the Lakehouse architecture.
Sometimes, the best solutions are the simplest. And in this case, two lines of SQL saved hours of rework.